Event Sourcing Anti-patterns: 10 Ways Your Event Store Will Ruin Your Quarter
"The single biggest bad thing that I have seen during the last ten years is the common anti-pattern of building a whole system based on Event Sourcing."

Greg Young popularized CQRS/ES. He says most teams should not use it. Here is what happens when they do anyway.
The Warning Nobody Reads
Greg Young popularized Event Sourcing and CQRS. He spent a decade watching teams adopt it. Then he said this:
“The single biggest bad thing that I have seen during the last ten years is the common anti-pattern of building a whole system based on Event Sourcing.”
He called it “effectively creating an event sourced monolith” and “a really big failure.”
Udi Dahan, another architect who shaped this space, went further: most teams implementing CQRS and event sourcing should never have adopted them. The effort they diverted could have gone toward actual business-value features.
These are the people who created this pattern. Yet conference talks keep selling event sourcing as the solution to everything. Blog posts promise “free audit logs” and “time travel.” Teams adopt it system-wide because one bounded context benefited from it.
This article is about what happens in year two.
I have collected production war stories, real code examples, and opinions from practitioners who shipped event-sourced systems and regretted it. If you are a tech lead about to adopt event sourcing because someone told you it “solves the audit problem,” read this first.
The Decision Checklist: Before You Commit
Not every system needs event sourcing. Most do not. Before reading the anti-patterns, answer these two questions honestly.
Question 1 (from Chris Kiehl): What concrete core problem does event sourcing specifically solve for you?
If your answer involves vague words like “auditability,” “flexibility,” or “future-proofing” -- stop. Those are not problems. Those are hopes. A traditional audit table delivers 80% of the value at a fraction of the cost.
Question 2: Is a simple queue actually sufficient?
Many teams adopting event sourcing actually need decoupled async processing. A message queue solves this without the append-only-forever-immutable-replay complexity.
Event sourcing IS the right choice when:
You need to reconstruct state at any point in time (financial ledgers, trading systems)
“What happened” drives business decisions, not just “what is the current state”
Your domain has complex business rules that depend on the sequence of past events
You operate in high-transaction domains: finance, gambling, logistics, compliance
Event sourcing is NOT the right choice when:
You want an audit log (use an audit table)
You want async communication between services (use a message broker)
You want to decouple reads and writes (use CQRS without event sourcing)
Your domain is fundamentally CRUD (user profiles, app config, CMS)
The 10 Anti-patterns
Anti-pattern 1: Property Sourcing (State-as-Events)
What it is. Events named after field mutations: LastNameChanged, EmailUpdated, MobileNumberProvided. You are recording what changed, not why.
Why it kills you. These events carry zero business value. Replaying them tells you nothing about business decisions. You have built a changelog, not an event-sourced system. Oskar Dudycz calls this “CRUD wearing an event costume.”
Bad:
{ "type": "LastNameChanged", "data": { "userId": "u-123", "lastName": "Smith" } }
{ "type": "EmailChanged", "data": { "userId": "u-123", "email": "new@example.com" } }
{ "type": "PhoneChanged", "data": { "userId": "u-123", "phone": "+1-555-0100" } }
Three events. Zero context. Was this a name change after marriage? A typo correction? A fraudulent account takeover? No way to tell.
Good:
{
"type": "UserCorrectedPersonalDetails",
"data": {
"userId": "u-123",
"changes": { "lastName": "Smith", "email": "new@example.com" },
"reason": "marriage",
"verifiedBy": "support-agent-42",
"timestamp": "2026-04-11T10:30:00Z"
}
}
One event. Full business context. You can answer “why did this change?” five years from now.
The fix. Name events after business operations, not field mutations. If you cannot name the business reason for the event, you are property sourcing.
Anti-pattern 2: CRUD-in-Disguise
What it is. Events named OrderCreated, OrderUpdated, OrderDeleted -- mapping database CRUD verbs directly to event types.
Why it kills you. You get the complexity of event sourcing with the expressiveness of CRUD. Your “events” carry no domain intent. Your audit log is useless for business analysis. Your team maintains two paradigms -- an event store AND a CRUD mental model -- for zero additional value.
Bad:
{ "type": "OrderUpdated", "data": { "orderId": "o-456", "status": "shipped", "trackingNumber": "1Z999..." } }
What happened? Something about the order changed. Maybe it shipped. Maybe the address was corrected. Maybe the customer upgraded to express. The event does not say.
Good:
{ "type": "OrderShipped", "data": { "orderId": "o-456", "carrier": "UPS", "trackingNumber": "1Z999...", "estimatedDelivery": "2026-04-15" } }
The test. If your event types end in Created, Updated, or Deleted, you are doing CRUD with extra steps. Rename them to what actually happened in the business domain.
Anti-pattern 3: The Event-Sourced Monolith (Event Sourcing Everything)
What it is. Using event sourcing as the top-level architecture for your entire system. Every bounded context, every service, every entity -- all event-sourced through a shared global store.
Why it kills you. Greg Young, the person who popularized this pattern, explicitly calls this the worst thing he has seen teams do. Not every domain benefits from event sourcing. User profile management? Application configuration? Notification preferences? These are CRUD domains. Forcing them into event sourcing wastes engineering time and adds needless complexity.
Worse: your persistence becomes your public API. Every bounded context adjustment is a breaking change for every downstream consumer.
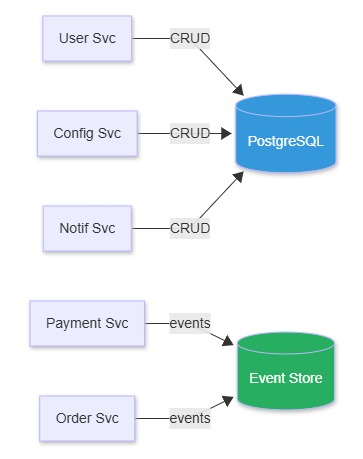
Diagram: The fix -- event-source only Payment and Order services. Everything else uses CRUD with PostgreSQL.
The fix. Event source only the bounded contexts where temporal queries and state reconstruction provide genuine business value. Use CRUD for everything else. Bridge with CDC where needed.
Anti-pattern 4: Event-as-Message Conflation
What it is. Publishing internal event-sourcing events (fine-grained persistence events) as the inter-service communication mechanism. Your internal persistence layer becomes your public API.
Why it kills you. Internal events like MobileNumberProvided, VerificationCodeGenerated, MobileNumberValidated capture registration steps. They exist for state reconstruction inside one bounded context. When you publish them externally, every downstream service must:
Understand your registration internals
Correlate multiple fine-grained events into one business fact
Filter out technical noise they do not care about
Break whenever you refactor your internal flow
Bad:
Registration Service publishes 5 internal events:
-> MobileNumberProvided
-> VerificationCodeGenerated
-> VerificationCodeSent
-> VerificationCodeValidated
-> UserAccountActivated
Downstream services subscribe to all 5, correlate by userId,
wait for the last one, and hope the order does not change.
Good:
Registration Service internally event-sources 5 events.
After completion, publishes 1 domain event:
-> UserRegistrationCompleted { userId, email, plan, timestamp }
Downstream services subscribe to 1 event. Done.
The principle (INNOQ): “Domain Events and Event Sourcing events are used for different purposes and should therefore not be mixed.” Internal events are for persistence. External events are for communication. Keep them separate.
Anti-pattern 5: Missing Snapshot Strategy (The Unbounded Replay)
What it is. Loading aggregates by replaying their entire event history from the beginning of time, without any snapshotting.
Why it kills you. Fine for the first six months. Then your busiest aggregate has 50,000 events and loading it takes three seconds. A background job without idempotency checks lets one aggregate quietly accumulate 100,000 events. “Editing a particular document got slower and slower” over months until it became unusable. Nobody notices until a user complains.
War story: A financial app stored every price tick (millions per day) as events. Reconstructing account balances required replaying 3 TB of data. Query times measured in minutes, not milliseconds.
The fix: Implement snapshots based on your domain access patterns:
Every N events (100-1000) -- General purpose. Trade-off: N too low = write overhead; N too high = slow reads.
Event-triggered (e.g.
ShiftEnded) -- Domains with natural checkpoints. Trade-off: only works for some domains.Time-based (hourly/daily) -- Predictable workloads. Trade-off: uneven processing between periods.
Performance threshold (replay > 100ms) -- Hot aggregates. Trade-off: requires monitoring infrastructure.
Store snapshots in a separate stream from events. Consider shorter-lived aggregates and domain-driven lifecycle boundaries before reaching for snapshots.
The real fix: Design aggregates with bounded lifetimes. An Order does not need 10 years of events. Close it. Archive it. Start fresh.
Anti-pattern 6: Schema Evolution Without a Plan (The Time Bomb)
What it is. Adding fields to events, changing event structure, or evolving business rules without a versioning strategy. Then replaying old events with new logic and watching the corruption unfold.
War story: A team added a discount_code field to OrderPlaced events. Old projections ignored it. A replay then applied 2024 discount logic to 2022 data. Customers received unintended discounts. Financial discrepancies appeared. The team had to choose between costly manual reconciliation and silently accepting the error.
Dennis Doomen’s team hit version _V5_ on some events: “The more versions you have of an event, the more of this knowledge dissipates into history.” Property length constraints evolved (product titles from 50 characters to unlimited), causing truncation or database errors on replay.
Why it kills you. Events are forever. Every event you write today will be read by code written three years from now. Without a versioning strategy, you are planting time bombs in your event store.
The fix: Choose a schema evolution strategy before writing your first event. See the dedicated section below.
Anti-pattern 7: Anemic Events / Fat Events
What it is. Two anti-patterns at opposite ends of the same spectrum.
Anemic events carry only an ID:
{ "type": "OrderPlaced", "data": { "orderId": "o-456" } }
The consumer knows an order was placed but has nothing to work with. It must call back to the Orders API to get details. This creates temporal coupling -- if the producer is down, the consumer cannot process anything. You have built synchronous RPC disguised as async events.
Fat events carry the entire world:
class OrderPlaced {
UUID orderId;
Cart shoppingCart; // Owned by Cart service
Address shippingAddress; // Owned by Shipping service
PaymentDetails payment; // Owned by Billing service
CustomerProfile customer; // Owned by User service
}
Every new requirement (Prime shipping? Bitcoin payments?) means modifying this shared event contract. Consumer state becomes stale when copied data changes after emission. You have created a distributed monolith through your event schema.
The fix. Events carry enough data for consumers to act independently, but only data the producer naturally owns.
{
"type": "OrderPlaced",
"data": {
"orderId": "o-456",
"customerId": "c-789",
"items": [{ "productId": "p-101", "quantity": 2, "unitPrice": 29.99 }],
"totalAmount": 59.98,
"placedAt": "2026-04-11T14:30:00Z"
}
}
IDs for entities owned by other services. Full data for what the Order service owns. Consumers use the IDs to enrich from their own data stores if needed.
Anti-pattern 8: Circular Event Dependencies (The Infinite Loop)
What it is. Events that trigger handlers that produce events that trigger handlers that produce events. Forever.
War story: A UserUpdated event triggered a ProfileUpdated event, which triggered another UserUpdated event. The system churned through 500,000 events per hour until it ran out of memory and crashed.

Diagram: Circular event loop -- UserUpdated triggers ProfileUpdated, which triggers UserUpdated again, infinitely.
The fix:
Causation IDs. Every event carries the ID of the event that caused it. Before processing, check whether you are already in the chain.
Chain depth limits. If an event chain exceeds N depth (say, 5), halt and alert. No legitimate business process needs 50 levels of event cascading.
Idempotency keys. Every handler checks: “Have I already processed an event with this causation chain?” If yes, skip.
def handle_event(event):
if event.chain_depth > MAX_CHAIN_DEPTH:
log.error(f"Circular dependency detected: {event.causation_id}")
alert_ops_team(event)
return
if already_processed(event.idempotency_key):
return
# Safe to process
process(event)
Anti-pattern 9: The Projection Maintenance Trap
What it is. Treating projections as “free read models” without accounting for the multiplicative maintenance burden.
Why it kills you. Chris Kiehl puts it bluntly: “Adding a second projection doubles the amount of code that touches your event stream. If you add, modify, or remove an event type, you’re on the hook for spreading knowledge of that change to N different places.”
With 5 projections and 20 event types, you have 100 potential touch points. Add a new event type? Update 5 projections. Change an existing event? Update 5 projections. Remove an event type? Update 5 projections. The DRY principle does not just bend -- it snaps.
Hidden production issues (Dennis Doomen):
Projectors develop dependencies on other projectors’ data. Rebuilding projection A reads stale data from projection B.
Idempotency gaps: “Event 20 required a projection to be deleted. After restarting at event 10, the process expected that projection to still exist.”
Materialization lag: “Newly created data will 404, deleted items will awkwardly stick around, duplicate items will be returned.”
The fix. Treat each projection as a maintenance liability, not a feature. Ask: “Is this read model worth the ongoing cost of keeping it synchronized with every event schema change?” Often the answer is no. Often a database view or a cached query is cheaper.
Anti-pattern 10: Ignoring GDPR Deletion Requirements
What it is. Building an immutable event store and then discovering that privacy regulations require you to delete personal data on request.
War story: A user exercised their GDPR right to erasure. The team faced an impossible choice: delete events from the “immutable” log (breaking audit trails and projections) or refuse the deletion request (breaking the law).
Why it kills you. Immutability and the right to be forgotten are fundamentally incompatible. If you did not plan for this, you are stuck with bad options:
Delete events: Breaks projections, corrupts audit trails, violates the core promise of event sourcing.
Overwrite events: You no longer have an immutable log.
Ignore the request: Your legal team will not enjoy this strategy.
The fix: Design for GDPR from day one.
Crypto-shredding. Encrypt PII with per-user keys. To “delete” data, destroy the encryption key. Events remain intact but PII becomes unreadable.
PII segregation. Store personal data in a separate, deletable store. Events reference tokens, not actual PII.
Pseudonymization. Replace real identifiers with pseudonyms. Map pseudonyms to real identities in a deletable lookup.
Event store (immutable, GDPR-safe):
{
"type": "OrderPlaced",
"data": {
"orderId": "o-456",
"customerToken": "tok_encrypted_abc123",
"items": [{ "productId": "p-101", "quantity": 2 }]
}
}
PII store (deletable):
{
"token": "tok_encrypted_abc123",
"name": "Jane Smith",
"email": "jane@example.com"
}
After GDPR deletion, the PII store entry is removed. The event still exists, but customerToken resolves to nothing.
Compliance is not retroactive. If you bolt GDPR support onto an existing event store, you are rewriting your persistence layer. Build it in from the start.
Production War Stories: Costs Nobody Warned You About
The 18-Hour Recovery
A projection corruption required replaying two weeks of events. The replay ran single-threaded. It took 18 hours. SLA violations stacked up. The fix: parallel replay by aggregate ID and blue/green projection maintenance. But the 18-hour outage had already happened.
The CI That Took Days
A team re-ran their event store in CI with a few million events. What started as a minutes-long test suite “eventually took DAYS to re-run the events.” The system would not have survived production. The fix: snapshotted test data and in-memory replay with single transactions (no disk writes per message). But those sprints were already burned.
The Upfront Sprint Tax
Chris Kiehl describes the reality: “Entire sprints lost to infrastructure planning before any application value could be delivered.” Classes for commands, command handlers, command validators, events, aggregates -- all before touching business logic. Meanwhile, the team using PostgreSQL and a CRUD model shipped features.
The UI Impedance Mismatch
Backend teams want small, semantic events. Frontends send fat blobs of form data. Most UIs are static and form-based. Bridging these two worlds creates a translation layer that somebody has to maintain forever.
Schema Evolution Strategies That Actually Work
You will need to evolve your event schemas. This is not optional. Here are the strategies that survive multi-year production use:
Strategy 1: Upcasting (The Recommended Default)
Transform old events into newer versions at read time. Chain upcasters: V1 -> V2 -> V3.
# Upcaster chain: each function transforms one version forward
def upcast_v1_to_v2(event):
"""Added 'currency' field in V2"""
return {
**event,
"version": 2,
"currency": "USD" # Default for pre-V2 events
}
def upcast_v2_to_v3(event):
"""Added 'notes' field in V3"""
return {
**event,
"version": 3,
"notes": "" # Default for pre-V3 events
}
# At read time, apply the chain
UPCASTERS = {
(1, 2): upcast_v1_to_v2,
(2, 3): upcast_v2_to_v3,
}
def load_event(raw_event, target_version=3):
current = raw_event
while current["version"] < target_version:
key = (current["version"], current["version"] + 1)
current = UPCASTERS[key](current)
return current
Pros: No data migration. Immutability preserved. Rollback is just a code change.
Cons: CPU cost grows with version distance. A V1 event going through 8 upcasters on every read adds up.
Strategy 2: Weak Schema (Tolerant Reader)
Events carry flexible JSON payloads. Consumers extract only fields they need and ignore unknowns. Adding fields never breaks existing consumers.
Pros: Maximum tolerance. No versioning infrastructure.
Cons: No compile-time safety. Silent failures when fields disappear. Hard to enforce contracts across teams.
Strategy 3: Lazy Migration (Old + New Coexist)
When domain understanding evolves significantly, introduce new event types alongside old ones. Projection logic handles both. New business logic emits only new types. Old events become historical artifacts.
Pros: Zero migration downtime. Gradual transition.
Cons: Projection logic grows monotonically. Every new event type adds permanent maintenance cost.
The Practical Recommendation
Use upcasting as your default. Add explicit version numbers to every event from day one. Test upcasters with real production event fixtures. When the upcaster chain gets long (5+ versions), consider a one-time copy-and-transform migration to reset the version baseline.
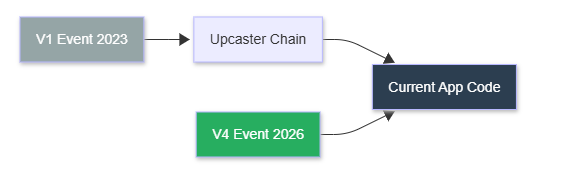
Diagram: Old V1 events pass through an upcaster chain to reach current code. New V4 events go directly to the app.
Alternatives for 80% of Cases
Most teams adopting event sourcing do not need event sourcing. Here is what they actually need.
Alternative 1: Audit Tables
A separate audit_log table alongside your CRUD tables. Records who, what, when, and why.
Complexity -- Event Sourcing: High, new architectural pattern. Audit Table: Low, extra table + triggers.
State reconstruction -- Event Sourcing: Full replay from events. Audit Table: Not designed for this.
Audit fidelity -- Event Sourcing: Theoretical 100% (degrades in practice). Audit Table: Good enough for compliance.
Query performance -- Event Sourcing: Requires projections + CQRS. Audit Table: Standard SQL queries.
Team learning curve -- Event Sourcing: Months. Audit Table: Days.
Infrastructure -- Event Sourcing: Event store + projection infra. Audit Table: Your existing database.
Chris Kiehl: “A traditional history table delivers 80% of the value of a ledger with essentially none of the cost.”
Alternative 2: CDC (Change Data Capture)
Capture changes from your database transaction log and forward them to downstream consumers. Tools: Debezium, AWS DMS.
You keep your CRUD model. You get event streams “for free” from your existing database WAL. No new persistence pattern to learn. Debezium + the Outbox pattern avoids dual-write problems.
CDC is “generally a more practical solution for your average developer team.”
Alternative 3: Append-Only Tables + Materialized Views
PostgreSQL append-only tables with materialized views for read optimization. Event sourcing on a complexity budget.
Full event sourcing scores roughly 41 complexity points across infrastructure, operational, and development dimensions. The simplified PostgreSQL approach scores roughly 13. Same concept. One-third the cost.
Alternative 4: The Hybrid (Greg Young’s Own Recommendation)
Event sourcing selectively. CRUD for everything else.
Event source: Payment ledgers, order processing, trading systems, compliance flows
CRUD: User profiles, app config, content management, notifications
Bridge with CDC: Feed CRUD changes into event streams where downstream services need them
This is what Greg Young actually recommends. “CQRS and Event sourcing are not top-level architectures and normally they should be applied selectively just in few places.”
The 2-Question Decision Framework
You saw these questions at the top. Here they are again -- this time with concrete examples of good and bad answers. If you cannot answer both clearly, use CRUD + audit tables.
Question 1: What concrete problem does event sourcing solve that nothing else can?
Acceptable answers:
“We need to reconstruct account balances at any historical point for regulatory audits”
“Our trading system must replay market events to verify execution correctness”
“Insurance claim adjudication depends on the exact sequence of submitted documents”
Unacceptable answers:
“Audit logs” (use an audit table)
“Flexibility” (flexibility for what?)
“It’s the modern best practice” (it is not)
“We might need time travel someday” (you will not)
Question 2: Is a simple queue sufficient for what you are actually trying to do?
If your real need is “Service A needs to tell Service B that something happened, asynchronously” -- that is a message queue. RabbitMQ. SQS. Kafka with a consumer group. You do not need an immutable, append-only, replayable event store for pub/sub.
The Bottom Line
Event sourcing is a powerful pattern for a narrow set of problems. It is not a general-purpose architecture. It is not a free audit log. It is not a silver bullet for distributed systems.
The people who created it say so themselves.
If you adopt event sourcing, adopt it for one bounded context where temporal queries provide clear business value. Staff it with engineers who have done it before. Budget for schema evolution, projection maintenance, snapshot infrastructure, and GDPR compliance from day one.
For everything else, use a database. Add an audit table. Ship the feature.